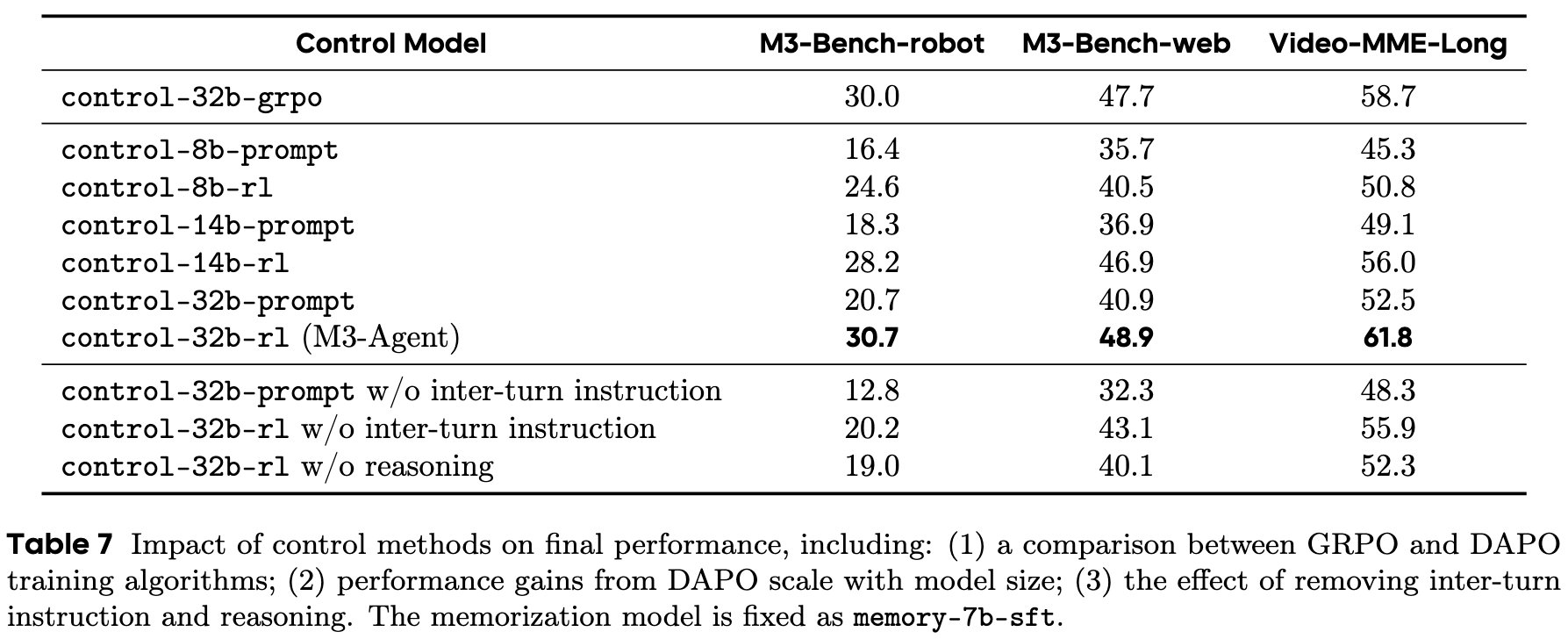
M3-Bench
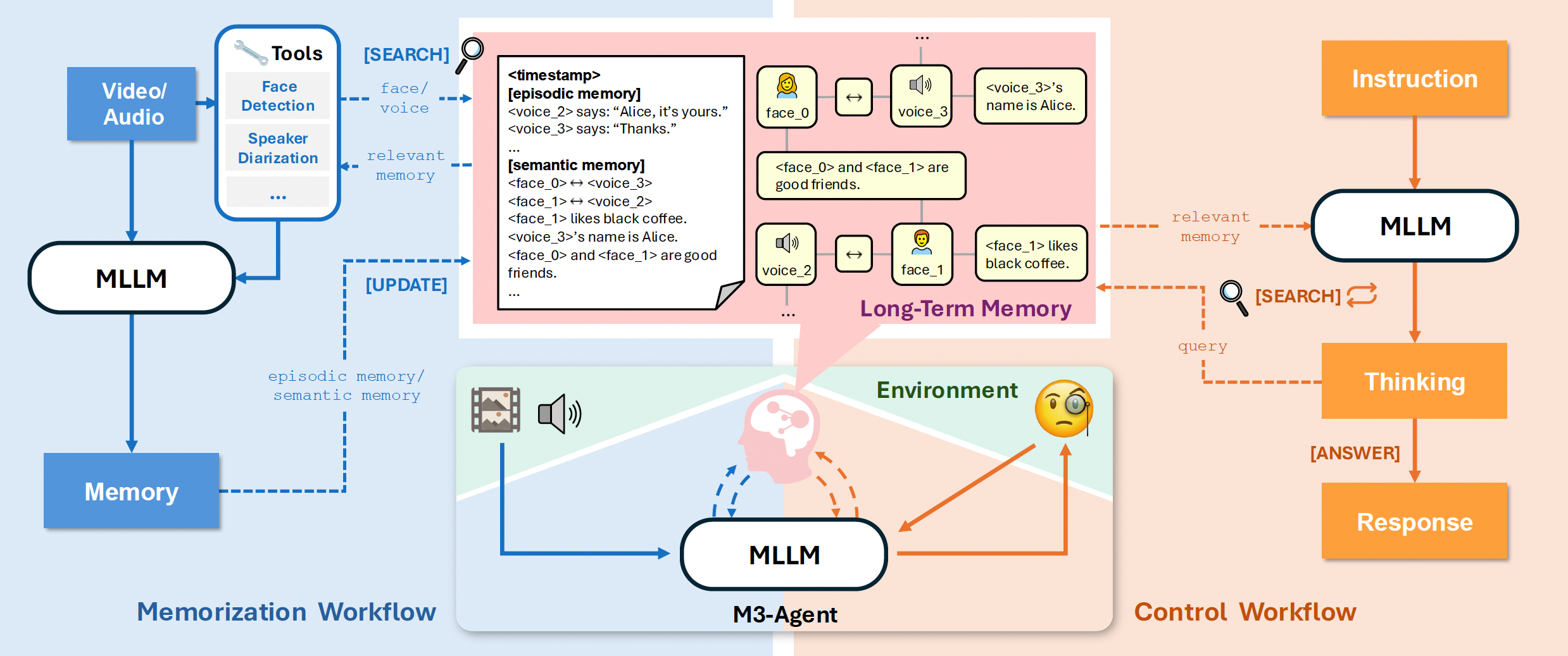
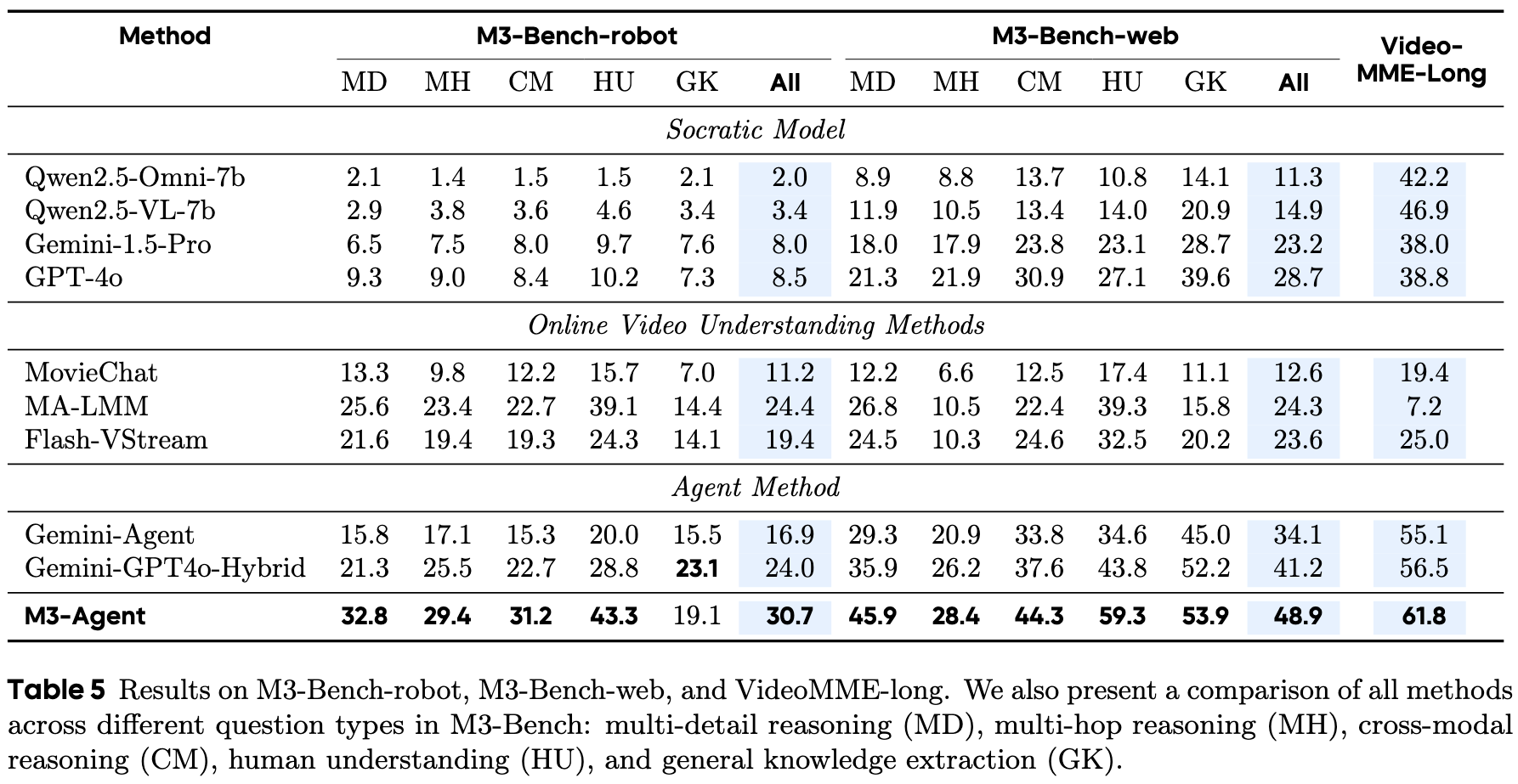
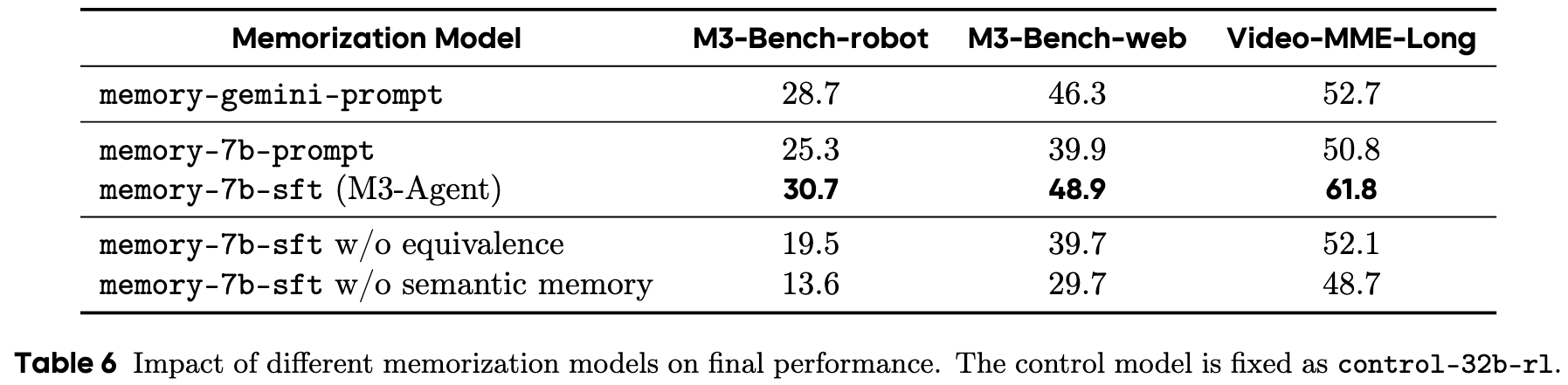
We introduce M3-Bench, an long video question answerin dataset designed to evaluate the capability of multimodal agents to perform reasoning over long-term memory. Each instance in M3-Bench comprises a long video simulating the perceptual input of an agent, along with a series of open-ended question-answer pairs. The dataset is organized into two subsets:
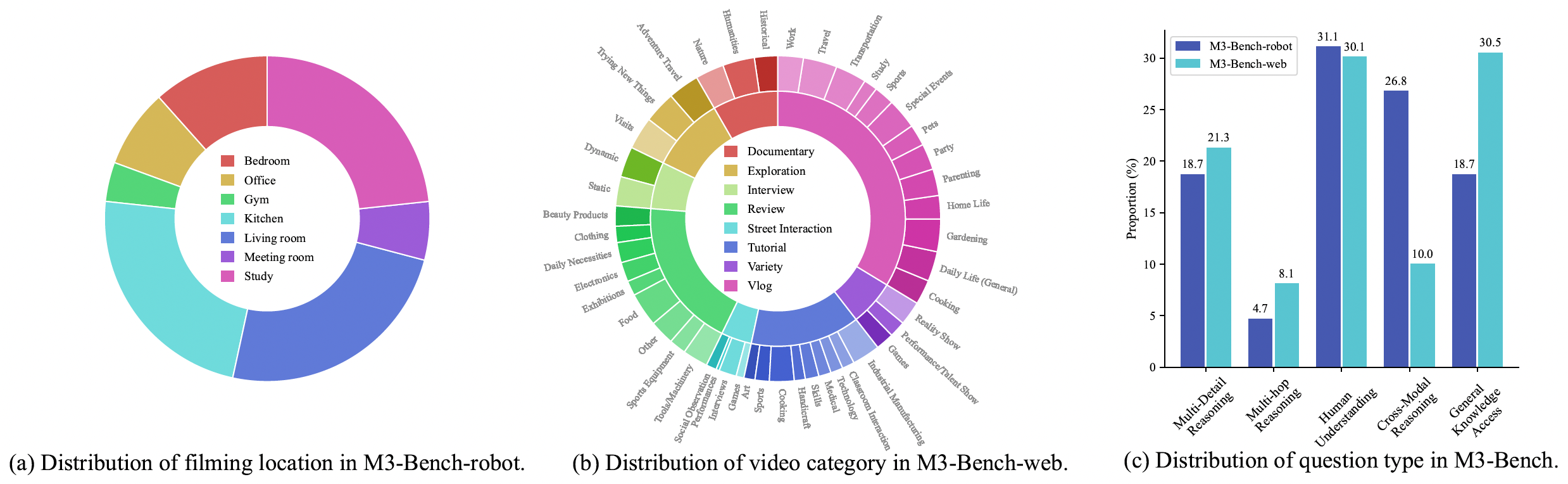
1. M3-Bench-robot, which contains 100 real-world videos recorded from a robot's first-person perspective,
2. M3-Bench-web, which includes 920 web-sourced videos covering a wider variety of content and scenarios.
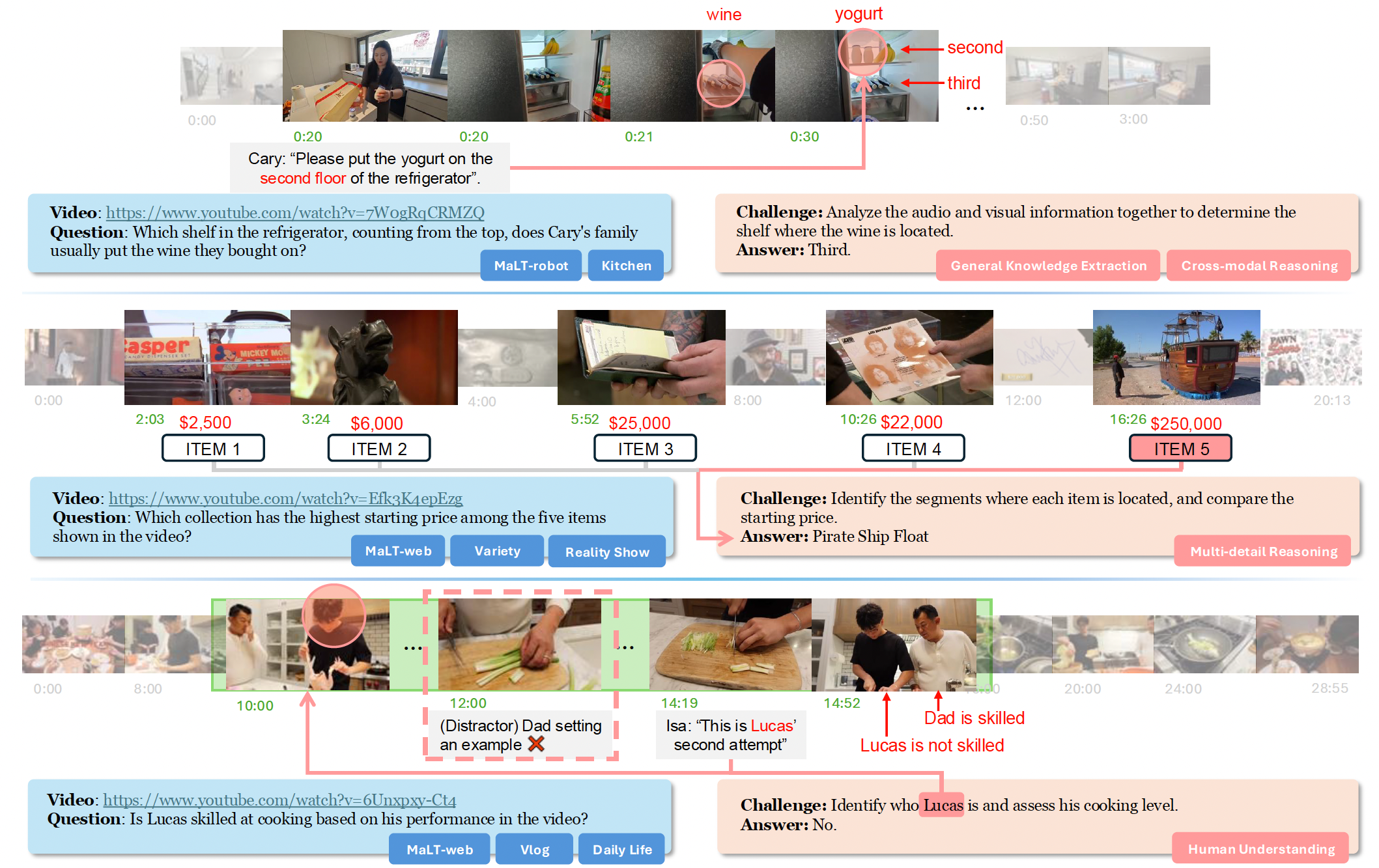
Examples from M3-Bench. M3-Bench-robot features long videos from realistic robotic work scenarios, while M3-Bench-web expands the video diversity to support broader evaluation. The question-answering tasks are designed to assess a multimodal agent’s ability to construct consistent and reliable long-term memory, as well as to reason effectively over that memory.